
はじめに
前回の記事で Kinesis Data Streams を使用する際の勘所をまとめました。その続編として本記事では、Kinesis Client Library (KCL) に関して得た知見を公式ドキュメントに沿ってまとめていきます。
前回の記事はこちら

Kinesis Client Library とは何ですか?
KCL はアプリケーションロジックと Kinesis Data Streams を仲介する働きを担い、具体的には以下を行います。
- データストリームに接続
- データストリーム内のシャードを列挙
- リーステーブルを作成して、シャードとそのワーカーとの関連付けを調整
- レコードプロセッサで管理する各シャードのレコードプロセッサをインスタンス化
- データストリームからデータレコードを取得
- 対応するレコードプロセッサにレコードを送信
- 処理されたレコードのチェックポイントを作成
- ワーカーインスタンス数が変更された場合、またはリシャードが発生した場合、シャードとワーカーの関連 (リース) の調停を実施
すなわち、KCL を利用することで分散処理を行うインスタンス間の連携やストリーミングデータをどこまで処理したかの管理をユーザー側で実装する必要がなくなるということですね。
使用可能なバージョン
現在、KCL 1.x と KCL 2.x の2つのバージョンが存在しています。
大きな違いは、KCL 2.x でのみ専用スループット(拡張ファンアウトコンシューマー)が利用できるという点です。
専用スループット (拡張ファンアウトコンシューマー)
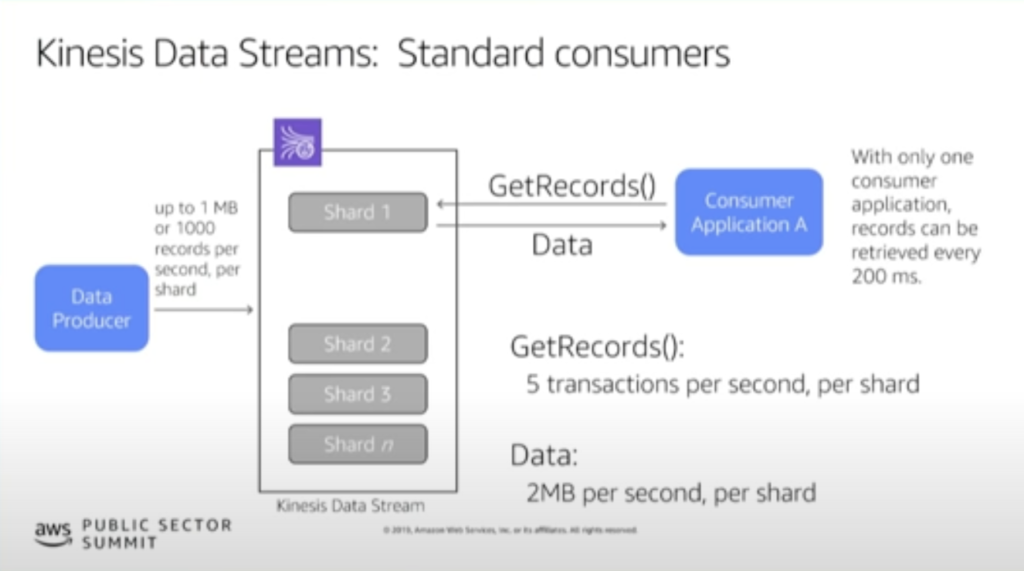
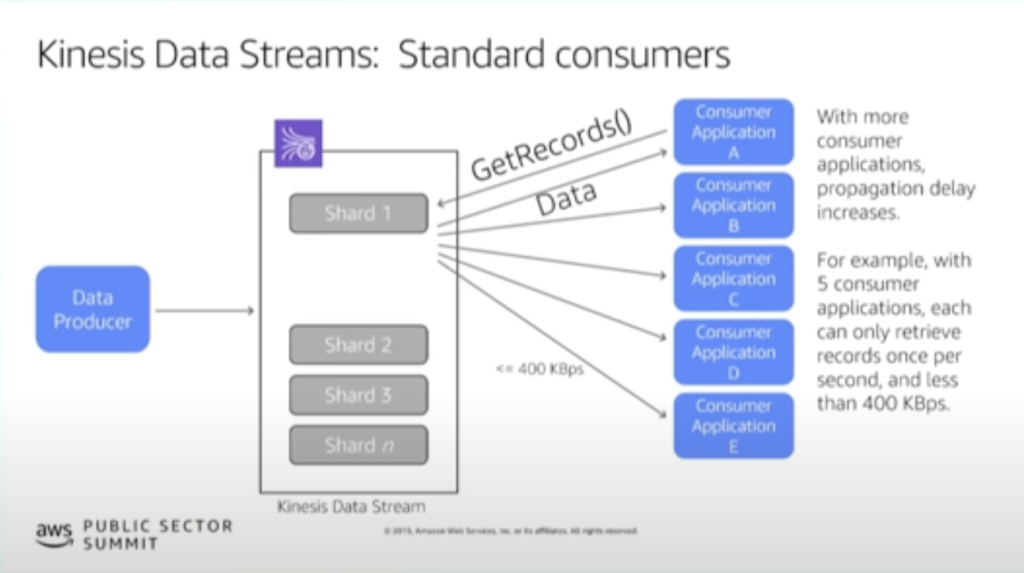
通常のコンシューマーは以下の特徴があります。
- GetRecords API を使ってデータストリームからデータを取得する
- シャードあたり毎秒5回までしか GetRecords できないため、最短で200msごとにデータ取得を行う
- 複数のコンシューマーが同一のシャードからデータを取得する場合、コンシューマーが増えるほど遅延が大きくなる
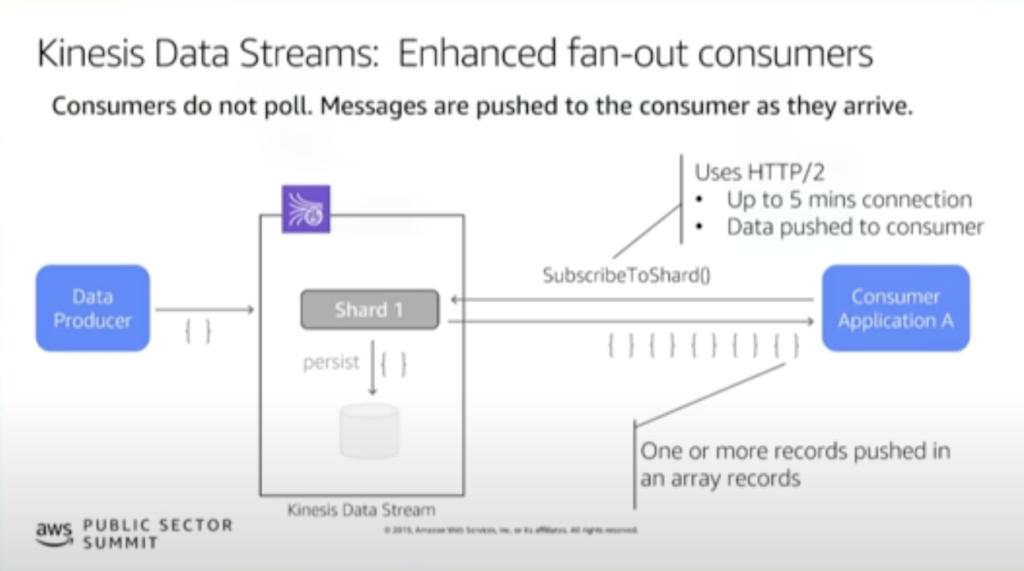
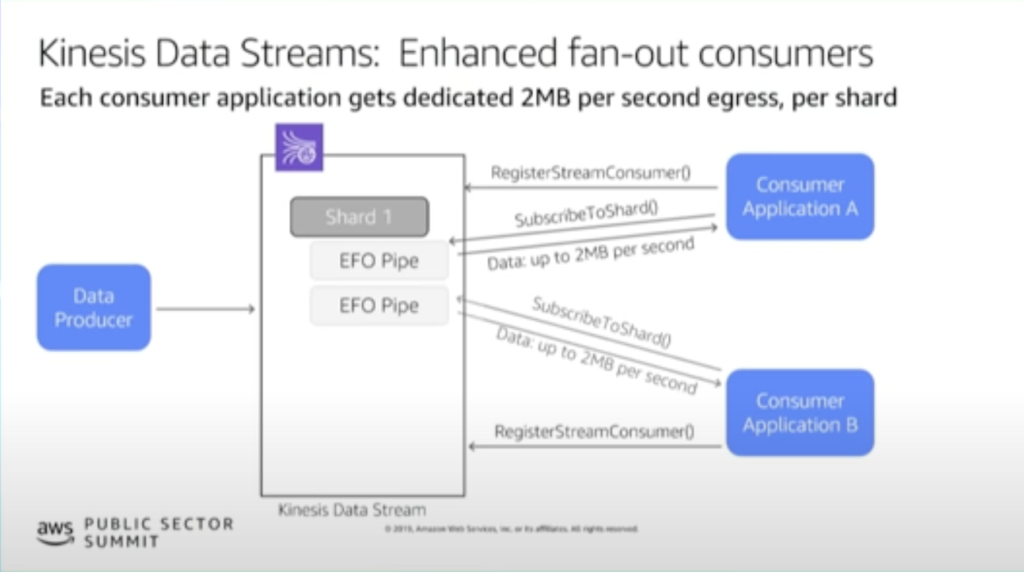
一方で拡張ファンアウトコンシューマーは以下の特徴があります。
- SubscribeToShard API を定期的に呼び出してサブスクリプションを更新
- データレコードは Kinesis Data Streams からコンシューマーに対してプッシュされる
- コンシューマーあたり、秒間2MBデータを受信可能で、他コンシューマーと干渉しない
拡張ファンアウトコンシューマーは通常のコンシューマーと比較して料金が高いため、上記の特徴を考慮した上でどちらを使用するか選択する必要があります。
KCLの概念
レコードプロセッサ
リースを保持するシャードごとに1つのレコードプロセッサがインスタンス化されます。
レコードプロセッサには、KCL コンシューマーアプリケーションがデータストリームから取得したデータをどのように処理するかを定義します。
リース
ワーカーとシャード間の紐付けを定義するデータ。KCL アプリケーションが存在する場合は、リースを使用して、複数のワーカーにまたがってデータレコード処理を行う。
※ KCL アプリケーションは1つのプロセスで対象のデータストリームの全てのシャードを受け持つことが可能ですが、シャード数が大量の場合は並列度が上がり、1つのプロセスでは処理しきれなくなる可能性があります。その場合に複数の KCL アプリケーションを立ち上げ負荷分散を行います。
リーステーブル
KCL は DynamoDB にリーステーブルを作成して、KCL アプリケーションのワーカーによってリースおよび処理される KDS データストリームのシャードを管理する。
※ KCL は KCL アプリケーション名と同じ名前でリーステーブルを作成します。そのため各 KCL アプリケーション名はリージョン内で一意である必要があります。
リーステーブルの項目
KCL が作成するリーステーブルの属性をまとめると以下になります。
- checkpoint: シャードの最新チェックポイントのシーケンス番号。この値は、データストリームのすべてのシャードで一意。
- leaseCounter: ワーカーのリースが他のワーカーに保持されていることをワーカーが検出できるように、リースのバージョニングに使用される。
- leaseKey: リースの一意な識別子。各リースはデータストリームのシャードに固有で、一度に一つのワーカーによって保持される。換言すると、複数のワーカーが一つのシャードを処理することはない。(例:shardId-000000000000)
- leaseOwner: このリースを保持しているワーカー。
- ownerSwitchesSinceCheckpoint: 最後にチェックポイントが書き込まれたときから、このリースが何回ワーカーを変更したかを表す。
- parentShardId: 子シャードで処理を開始する前に、親シャードが完全に処理されていることを確認するために使用される。これにより、レコードがストリームに投入されたのと同じ順序で処理されることが保証される。(リシャーディング後のデータのルーティング、データの永続化、シャードの状態)
- hashrange(KCL1.14およびKCL2.3のみ): PeriodicShardSyncManagerによって使用され、定期的な同期を実行してリーステーブルに欠けているシャードを見つけ、必要に応じてシャードのためのリースを作成する。
- childshards(KCL1.14およびKCL2.3のみ: LeaseCleanupManagerが子シャードの処理状況を確認し、親シャードをリーステーブルから削除できるかどうかを判断するために使用される。
スループット
KCLアプリケーションによって自動的に作成されるリーステーブルの、プロビジョニングされるスループットは1秒あたりの読み込み10回、1秒あたりの書き込み10回に設定されています。
シャード増加に伴いチェックポイントテーブルへのアクセス頻度も増加するため、キャパシティが不足する可能性があります。
キャパシティが不足するとチェックポイントの記録でエラーが発生するようになるため、運用でシャード増加に合わせて RCU、WCU を増加させるか、オンデマンドモードに変更する必要があります。
Python での Kinesis クライアントライブラリコンシューマーの開発
KCL 2.x を使用する場合、レコードプロセッサの処理を、Java または Python で記述することが可能です。KCLは Java ライブラリであるため、Python で記述する場合もJavaのインストールが必要です。
Python で記述したい場合、KCL for Python のサンプルが GitHub に存在します。Release Notes を見れば KCL のバージョンと amazon-kinesis-client-python の対応がわかります。
設定プロパティに関して、注意が必要な点を補足します。
idleTimeBetweenReadsInMillisは KCL 1.x を使用する場合は有効だが、KCL 2.x を使用する場合は無効 (上述したように KCL 2.x はデータストリームをポーリングしないため)initialPositionInStreamをTRIM_HORIZONに設定することでストリーム内の古いデータから処理される (デフォルトでは起動後に発生したデータから処理を行う)
リシャーディング、拡張、並列処理
リシャーディングが行われると、ワーカーはシャードからのデータを処理するためにプロセッサを作成します。そして、シャードに対して利用可能なすべてのワーカーおよびレコードプロセッサの割り当てを行います。
インスタンス数>シャード数の場合、超過した分のインスタンスはシャードに割り当てられることなく遊んでしまうため、 障害に対するスタンバイを考慮しないのであればインスタンス数はシャード数以下にするのがコスト最適になります。
アプリケーションの処理性能を向上させる方法としては以下の3つを組み合わせて対応を行います。
- インスタンスのスケールアップ (インスタンスの処理性能が向上する)
- インスタンスのスケールアウト (シャードと1:1に対応させることで、シャードを個別に処理できる)
- シャードのスケールアウト (並列度が向上する)
おわりに
公式ドキュメントの中から、Kinesis Client Library (KCL) を使用する際に注意が必要な点を整理してまとめました。この記事がどなたかの参考になれば幸いです。
参考
- Kinesis Client Library の使用 – Amazon Kinesis Data Streams
- DevAx::connectシーズン 1「イベント駆動」第5回 Near Real-Time Analytics を実現するアーキテクチャーと実装
- High Performance Data Streaming with Amazon Kinesis: Best Practices and Common Pitfalls
- リシャーディング後のデータのルーティング、データの永続化、シャードの状態
- GitHub – awslabs/amazon-kinesis-client-python: Amazon Kinesis Client Library for Python


コメント