はじめに
以前の記事で、Python と Notion API を利用して、英単語を検索して意味をノートにメモする作業を自動化しました。これをより利用しやすくするために、LINE から登録が行えるようにしたので、その手順についてまとめます。
前回の記事はこちら

環境
インフラにはAWSを使用し、API Gateway、Lambda を使用したサーバレス構成にしています。
$ python -V
Python 3.7.10
$ pip -V
pip 20.2.2 from /usr/lib/python3.7/site-packages/pip (python 3.7)
$ pip list | grep beautifulsoup4
beautifulsoup4 4.10.0
$ pip list | grep notion-client
notion-client 0.8.0
$ pip list | grep requests
requests 2.25.1対象者
この記事は下記のような人を対象にしています。
- スクレイピングで英単語の意味を取得したい人
- 検索した結果を Notion にまとめたい人
- AWS を使用した LINE Bot を作成したい人
手順
全体構成
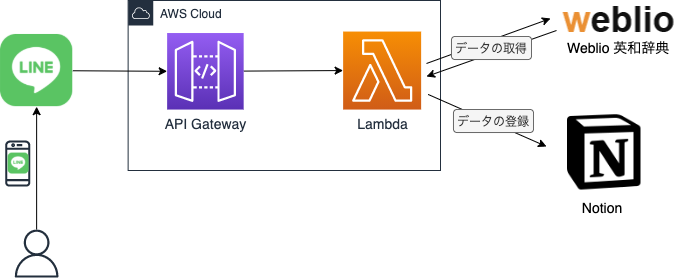
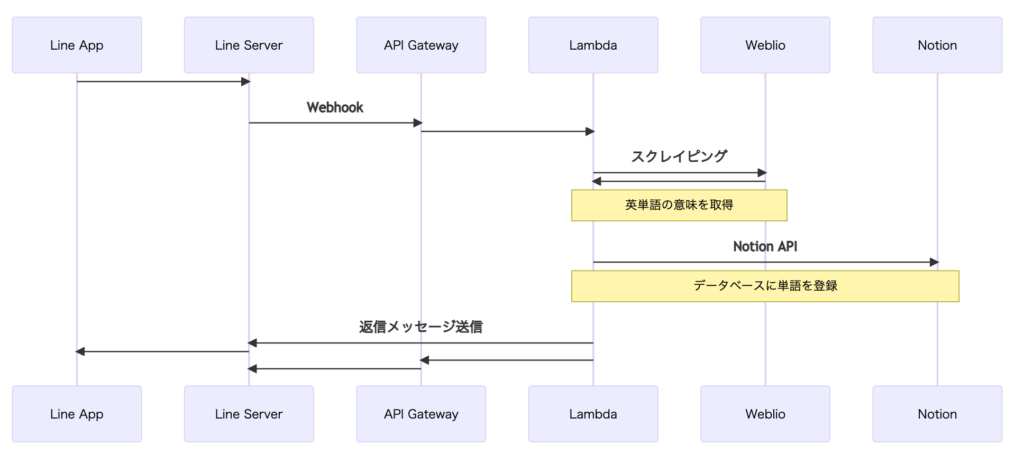
Notion API の設定を行う
公式ドキュメントを参考に、Notion API の設定の設定を行います。
Internal Integration Token は Notion API を叩く際に必要になるので、セキュアに保管してください。
今回は SSM パラメータストアに保存します。
データベース情報を取得する
Notion API を使用してデータベースにレコードを作成するために、登録するデータベースの ID が必要です。
データベースの ID は Notion の URL から確認可能です。
今回は SSM パラメータストアに保存します。
https://www.notion.so/myworkspace/a8aec43384f447ed84390e8e42c2e089?v=...
|--------- Database ID --------|LINE Bot を作成する
LINE Botの作成はボットを作成する | LINE Developersを参考に行います。AWS にデプロイする方法については LambdaではじめてのLINE Botを作る | DevelopersIOが大変参考になりました。
発行したチャンネルアクセストークンは SSM パラメータストアに保存します。
上記ブログの他、今回の英単語登録Botで設定した内容について補足します。
Lambda 関数
下記のプログラムを登録に使用しました。
- Weblio英和辞典の URL が “https://ejje.weblio.jp/content/brainteaser/{検索語}”になっていることを利用してリクエスト
- Weblio英和辞典へのリクエストのレスポンスから発音、意味を取得し、またWeblio英和辞典の URL もあわせて Notion に登録
- 登録の成功・失敗に応じて異なるメッセージを LINE に送信
lambda_function.py
import json
import logging
import os
import boto3
import requests
import create_item
logger = logging.getLogger(__name__)
logLevel=logging.DEBUG
logger.setLevel(logLevel)
url = 'https://api.line.me/v2/bot/message/reply'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer ' + create_item.access_token
}
def lambda_handler(event, context):
for message_event in json.loads(event['body'])['events']:
logger.debug(message_event)
word = message_event['message']['text']
try:
create_item.create_item(word)
text = f'{word}を登録したよ'
except:
text = '登録でエラーが発生したみたい...'
body = {
'replyToken': message_event['replyToken'],
'messages': [
{
'type': 'text',
'text': text,
}
]
}
req = requests.post(url, data=json.dumps(body).encode('utf-8'), headers=headers)
return {
'statusCode': 200
}create_item.py
import logging
import sys
import boto3
from bs4 import BeautifulSoup
from notion_client import Client
import requests
#SSM
ssm = boto3.client('ssm')
access_token: str = ssm.get_parameter(Name='/linebot/vocabulary/access_token',WithDecryption=True)['Parameter']['Value']
notion_token: str = ssm.get_parameter(Name='/linebot/vocabulary/notion_token',WithDecryption=True)['Parameter']['Value']
database_id: str = ssm.get_parameter(Name='/linebot/vocabulary/database_id',WithDecryption=True)['Parameter']['Value']
notion = Client(auth=notion_token)
url='https://ejje.weblio.jp/content/'
def search_weblio(word):
response = requests.get(url+word)
soup = BeautifulSoup(response.text, 'html.parser')
return soup
def parse_item(word):
soup = search_weblio(word)
pronunciation = soup.find(class_='phoneticEjjeDesc').get_text() if soup.find(class_='phoneticEjjeDesc') else ''
japanese = soup.find(class_='content-explanation ej').get_text().strip()
properties = {
'Word': {
'title': [{
'text': {
'content': word
}
}]
},
'Pronunciation': {
'rich_text': [{
'text': {
'content': pronunciation
}
}]
},
'Japanese': {
'rich_text': [{
'text': {
'content': japanese
}
}]
},
'Weblio': {
'url': url+word
},
}
return properties
def create_item(word):
properties=parse_item(word)
r = notion.pages.create(
**{
'parent': {'database_id' : database_id},
'properties': properties
}
)
if __name__ == '__main__':
create_item(sys.argv[1])Lambda レイヤー
Lambda 関数内の処理で使用するライブラリ(beautifulsoup4、notion-client、requests)の Lambda レイヤーを作成します。
Lambda レイヤーの作成に関しては過去にまとめていますので、そちらを参考にしてください。

動作確認
LINE アプリから 英単語を Notion に登録できることが確認できました。
おわりに
今回は LINE、AWS、Notion API を利用して、英単語を検索して意味をノートにメモする作業を自動化しました。英語学習の効率化にお役立てください。この記事がどなたかの参考になれば幸いです。


コメント